Ord fanget i nett
AV HELGE DYVIK
I begynnelsen var ordet, vet vi – men i utviklingen av metoder for automatisk språkanalyse innenfor datalingvistikken trådte det likevel i bakgrunnen en stund. På 70- og 80-tallet var både datalingvistikken og den formelle lingvistikken mest opptatt av måtene ord kan kombineres på, og mindre av de enkelte ord. Det ble utviklet gode modeller for syntaktisk beskrivelse og automatisk syntaktisk og morfologisk analyse, og interessante teorier om hvordan betydningene av fraser og setninger kan regnes ut på grunnlag av setningsdelenes betydninger. Men det ble stadig tydeligere at den store barrieren mot å ta dette i praktisk bruk i stor skala var mangelen på omfattende informasjon om ordforrådet i språket og de enkelte ordenes grammatiske og semantiske egenskaper. Skal et oversettelsessystem oversette «retten er satt» til engelsk, er det ikke nok at det kan finne subjekt og predikat. Det må også ha informasjon om de ulike betydninger «retten» kan ha, fra matrett til utsiden av en genser, og dessuten kunne velge riktig betydning i konteksten. Samme ferdighet ønsker vi oss i et intelligent informasjonssøkningssystem, som i tillegg gjerne bør kunne finne frem til andre ord med lignende betydning – for da kan det finne flere interessante dokumenter.
Slik fikk ordet en renessanse mot slutten av 80-tallet. Ordsemantikk kom mer i sentrum for forskernes interesse, og utviklingen av leksikalske databaser ble en prioritert oppgave. Blant slike databaser er ordnett kommet i forgrunnen for interessen i de senere år. Et ordnett er en orddatabase der ordenes ulike betydninger er utskilt og likeartede betydninger er gruppert sammen. Videre er ulike typer semantiske relasjoner mellom ordbetydningene markert, f.eks. hyponymi (hest er et hyponym til dyr), antonymi (god er et antonym til dårlig) og flere.
Det mest kjente ordnettet er det engelskspråklige WordNet ved Princeton-universitetet. En stab av medarbeidere har bygget det opp over flere år under ledelse av psykologen George A. Miller. Opprinnelig var det tenkt som et redskap i kognitiv psykologisk forskning, men i praksis er det først og fremst blant språkteknologer det har vakt interesse. Blant annet er det mye brukt i utviklingen av programmer som skal kunne avgjøre hvilken betydning et flertydig ord har i en konkret kontekst – såkalte disambiguerings-programmer. Etter hvert er flere ordnettprosjekter kommet til også i Europa.
Men oppbyggingen av ordnett er ingen liketil oppgave – den er beheftet med både praktiske og teoretiske problemer. Et stort praktisk problem er oppgavens omfang: Det tar mange årsverk å behandle hovedtyngden av ordforrådet i et språk på denne måten. Et annet problem er det usikre og subjektive i den enkelte ordnettmedarbeiders vurdering av ordbetydninger og deres relasjoner. Dette bunner igjen i det sentrale teoretiske problemet: tvilen på at ord i naturlige språk overhodet har et avgjørbart antall ulike betydninger som man kan isolere og beskrive en gang for alle. Hvordan man inndeler et ords semantiske potensial i delbetydninger, vil snarere være avhengig av teksttype og sammenheng, og av hensikten med inndelingen.
Alt dette gjør det fristende å lete etter metoder for å bygge ordnett mer eller mindre automatisk på grunnlag av språklige data. Kan vi klare å fravriste tekster informasjon om hvordan ordene i dem forholder seg til hverandre semantisk? Finnes det mønstre her som dataprogrammer kunne oppdage? Hvis vi klarer det, kan vi lettere bygge ulike ordnett over betydningsrelasjonene i ulike teksttyper, og vi kan kanskje redusere innslaget av subjektivitet og innsatsen av årsverk i oppgaven.
En særlig interessant teksttype i denne sammenheng er oversettelser – parallellstilt med originaler på et annet språk. I et slikt parallellkorpus av originaler og oversettelser ligger mye latent informasjon om ordbetydninger. Oversettelser blir til ved at høyt kvalifiserte tospråklige eksperter – oversettere – vurderer betydningen av ord og uttrykk i en konkret tekstsammenheng, og deretter gjengir den på et annet språk. Mye taler for at dette blir mer pålitelige vurderinger enn de som gjøres av ordnettbyggere med utgangspunkt i isolerte ord og intuisjoner om hva de kan bety. Og resultatet av vurderingene er et par av tekster med et nettverk av oversettelsesforbindelser seg imellom, der ord i originalen ofte er forbundet med ord i oversettelsen, fraser med fraser, og setninger med setninger. Hvis dette nettverket gjøres tilgjengelig for en datamaskin, kan vi da få den til å regne ut semantiske relasjoner i hvert av språkene på grunnlag av det?
I prosjektet «Fra parallellkorpus til ordnett» ved Universitetet i Bergen undersøker vi denne muligheten, og tar utgangspunkt i det engelsk-norske parallellkorpuset ENPC, utviklet av professor Stig Johansson og hans medarbeidere. Den grunnleggende antagelsen er at jo nærmere to ord står hverandre betydningsmessig, desto flere oversettelser bør de ha felles. Og hvis et ord (som f.eks. snill) er oversatt til bare en undermengde av de ordene et annet ord (f.eks. god) er oversatt til, så bør det første ordet være et hyponym – et underbegrep – til det siste. Videre antar vi at hvis et ord har to helt ubeslektede betydninger, så kommer også dette til syne i nettverket av oversettelsesforbindelser. Et eksempel er tak, som kan bety både toppen av et hus og et grep. I ENPC er dette ordet bl.a. oversatt med roof, ceiling, hold og grip. Hvis vi nå ser på oversettelsene av disse ordene til norsk igjen, kommer det frem at roof og ceiling hører sammen, og at hold og grip hører sammen, i hver sine grupper, ettersom roof og ceiling har oversettelsen hvelving felles, og hold og grip har oversettelsen grep felles. Men ingenting bortsett fra tak knytter roof eller ceiling til hold eller grip. Omtrent slik (utregningen er litt mer kompleks) fremkommer det at tak har to ulike betydninger.
Denne utskillingen av ubeslektede betydninger er første trinn i dataprogrammet. Deretter grupperes betydningene sammen i ‘semantiske felter’ på grunnlag av felles oversettelser. I slike felter skiller ord med vid betydning (som god) seg ut fra ord med snevrere betydning (som velsmakende) ved at ordene med vid betydning har flere ulike oversettelser enn de snevre. På grunnlag av slike mønstre blir de ulike betydningene automatisk forsynt med beskrivelser i form av trekk – desto flere trekk jo snevrere betydning – og disse beskrivelsene gjør det så endelig mulig å regne ut gitterstrukturer («semilattices») som (hvis vi har rett) viser nærsynonymi- og hyponymirelasjoner mellom betydningene.
Gitterstrukturene blir store og komplekse, men et par små utsnitt kan tjene til illustrasjon. k-nodene i gitrene representerer ‘virtuelle overbegreper’ – den betydning ordene under nodene har felles, men som "tilfeldigvis" ikke uttrykkes av noe eget ord i språket. De tjener til å knytte nettverket sammen. Strukturen i figur 1 domineres høyere oppe i gitteret av ordet stor; betydningene her bør altså være underbetydninger av ‘stor’.
Hvis denne metoden viser seg å ha noe for seg når vi utprøver den i større skala, kan informasjonen i slike nettverk danne grunnlag for å bygge et norsk ordnett, til nytte i mange språkteknologiske sammenhenger.
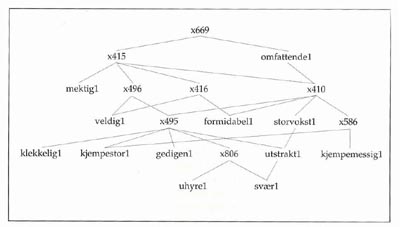
Figur 1. Noe av gitteret under stor.
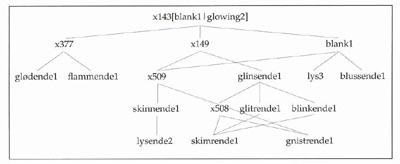
Figur 2. Gitteret under trekket [blank1|glowing2], der blank1 er «hode».
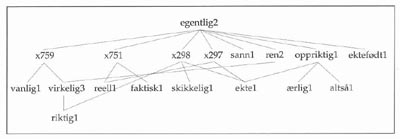
Figur 3. Gitteret under egentlig2
-- Helge Dyvik er professor i allmenn lingvistikk ved Universitetet i Bergen.
Del denne siden

